
New GenAI models are rolling out so rapidly it’s almost impossible for anyone with another job to keep up with them. In fact, we were already drafting this article when we started seeing references to new OpenAI models popping up on measures.
This is because, as Bleeping Computer reports, OpenAI is currently testing GPT-5, and it could show up any day now.
If what we’ve heard about it is right, GPT-5 will combine reasoning with the advances of GPT-4.5, amounting to a large step forward. (OpenAI is also reportedly testing o3-alpha, which is to be better than o3 and o3-pro in coding and front-end design work.)
So, it may go without saying that much of what’s in today’s article specific to certain LLMs and providers could soon be outdated.
With purely functional names, interfaces that default to a base model (typically not the most advanced), and models often shifting between pricing plans without fanfare, it’s no wonder so many people are confused about why and when to toggle to a new model.
Even at PTP, where we make our own AI solutions and are also avid AI users at work, we regularly find ourselves at a loss for what models to pick and why.
To that end, our goal today is to share what we’ve learned, and also what we’ve come across in research from a variety of quality sources, all with the aim of helping you try new models for new tasks to maximize your GenAI experience.
First, a couple of caveats—we’re focused here on chatbots, a very specific (if still most widely used) approach to GenAI, and we also don’t factor in the cost of input and output tokens, which varies wildly and is highly relevant for companies doing work at scale.
(For these comparison numbers, you can check out calculators like this one or the llm-stats leaderboard we’re using in our table below.)
But without further ado, here’s our look at the top AI tools for productivity in the chatbot arena today.
The Problem: There Is Still No One Best AI Model for Everything
It’s a strange time in GenAI, in that the frontier models are still quite good at most things (not super specialized), and yet focuses are emerging, both within companies and between their products.
And as mentioned above, their names don’t help. Linguistically, Claude 4 vs GPT-4o vs GPT-4.5 vs Gemini 2.5 Pro Preview TTS vs o4-mini-high isn’t going to tell you much about what they do best, and assuming the higher number is better isn’t always accurate.
Benchmarks, too, are a flawed measure, at least as a stand-alone option, as some companies appear to more aggressively train to excel on certain ones than others.
[For more on this, check out our most recent bi-monthly AI Roundup, where we looked at recent research on benchmark gaming by big providers.]
Nevertheless, the LLM industry is booming, with the biggest providers continuing to roll them out as fast as possible.

Questions to Ask to Choose the Right AI Model
There’s a lot of subjectivity in most of these measures, but there are also real functional considerations to keep in mind. For example, you can begin by asking yourself:
- What modalities will you need? Does text cut it? Voice, code, vision? How are you going to be interacting most? Will you need integrated image and video output and the ability to move back and forth with coding? What about agent capability for tool use?
- How important is accuracy vs reasoning? Your tolerance for hallucination in the use case is very important, as some of the latest reasoning models like OpenAI’s o3 show much higher error rates than prior (non-reasoning) models.
- Cost obviously is critical. While basic chatbot use is free—including for basic web search or online research through services like Perplexity—many of the features and models we discuss here require the $20/month ballpark for the entry-tier of paid pricing plans. If you’re experimenting and getting your feet wet, it’s worth this expense to at least try most of the models with features like Deep Research, coding, and video generation.
- Privacy is also variable among the models. While only Anthropic doesn’t train on your data by default, you can modify the settings in most to achieve this if you’re doing self-directed work. Among the providers considered here, xAI has the least transparency in this arena to date
- Use cases (i.e., Which AI model is best for writing?) are also to be considered. We’ll detail some below, but it’s best to begin with three or more real work scenarios you can use to test with (that nevertheless don’t spill proprietary data).
The top LLMs today in these categories come from just a handful of providers, and generally that means OpenAI, Google DeepMind, and Anthropic, and for some measures, xAI’s Grok with its newest release. Let’s take a look.
An AI Model Comparison
Below we attempt to merge approaches for a look at how top provider models are holding up, using: The Wharton School Associate Professor (and AI researcher) Ethan Mollick’s AI recommendations; Fello AI model selector advice (their product lets users swap models via their macOS chatbot); and AI benchmark tools like llm-stats (aggregates at release across measures) and the open LMArena, created by UC Berkeley researchers.
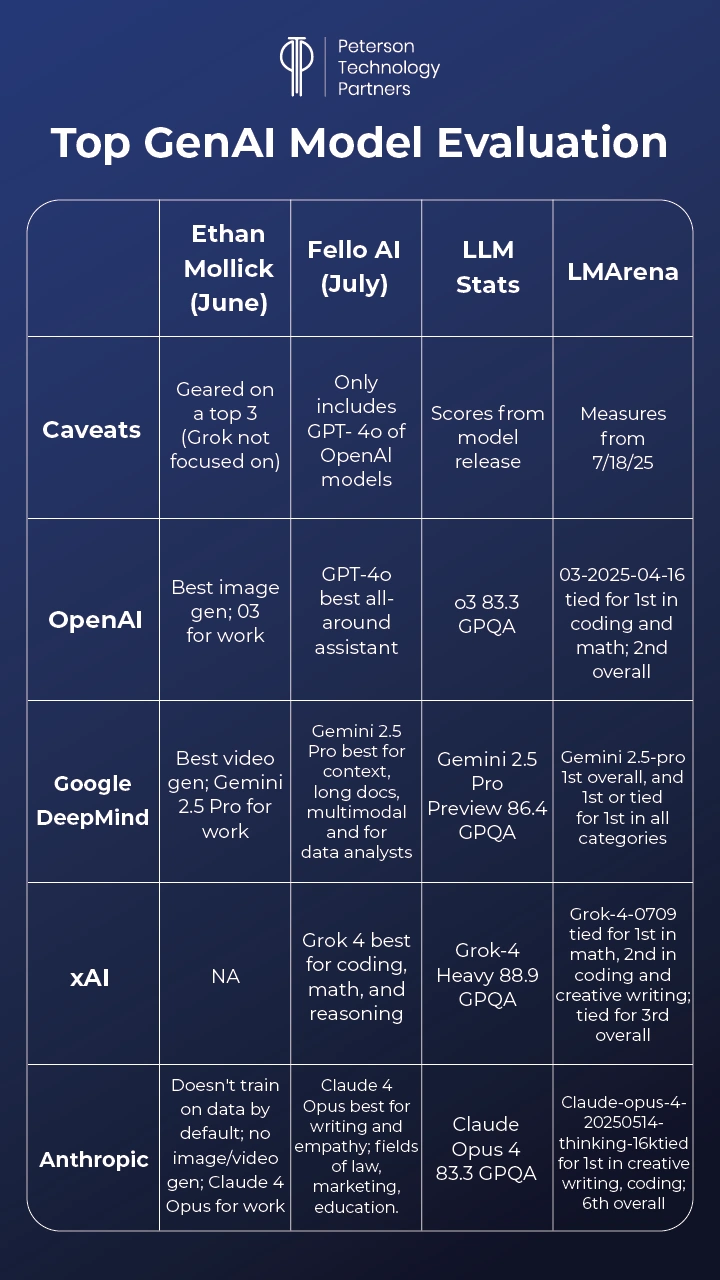
OpenAI: ChatGPT 4o vs o3
The OpenAI interface is simple and streamlined, but you arrive in-chat with very little explanation and a dropdown likely defaulted (at the time of this writing) to GPT-4o.
By clicking the dropdown, you can sometimes find yourself surprised (as in all of these services) by the arrival of new options, and each has minimal explanation. OpenAI gives you the most options, and even a “More models” choice which includes GPT-4.5 (in “research preview” at the lower tier with limited use).
And there are large differences between the choices here, with OpenAI’s lowest tier providing a full suite of options, with great multimodal support (including voice mode, image, video integrated).
You can upload files, and access other tools below the chat, including Deep Research (see below) which cuts across models.
So… why pick one vs the other?
In general, 4o is good for lightweight chat, and o3 for harder tasks, but there’s more nuance than this.
Looking to founding OpenAI researcher (and former Tesla Director of AI) Andrej Karpathy’s AI insights is a nice starting place. You can check the post for details, but it’s well summarized in this posted visual:
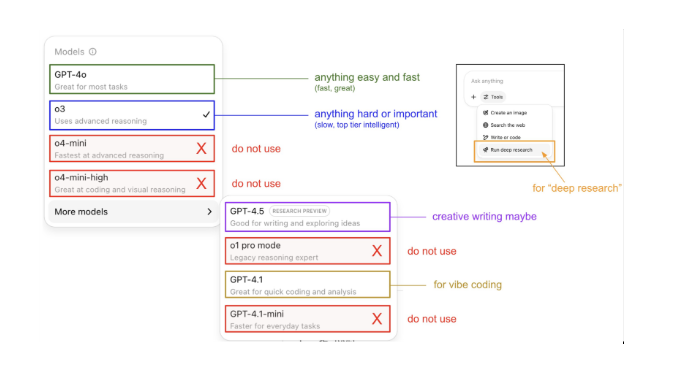 Pretty obvious, right?
Pretty obvious, right?
Anthropic’s Claude 4 Opus, or Is It Claude Opus 4?
Speaking of naming, the naming convention recently changed at Anthropic, between Claude [number] [model] to Claude [model] [number], so if you get your order confused on Claude 4 Sonnet or Claude Sonnet 4, no one will blame you.
Nevertheless, since Claude 4 arrived on the scene, it’s quickly become regarded as one of the best all-around models and claims to provide the best coding capabilities.
Anthropic is also often regarded as providing the best models for creative writing, and Claude Opus 4 carries on this tradition well.
Their models do often perform worse on some benchmarks than rivals, and Claude Opus 4 has a smaller context window than other top options (at 200,000 characters base at this time, vs Gemini 2.5-Pro’s one million for example).
Anthropic’s offerings also lack built-in image and video generation, which can be a significant drawback depending on your use case.
For practical use, it’s a simpler selection process than OpenAI, with Claude 4 Sonnet being the lighter weight option that’s good for most chat queries. Claude 4 Opus boasts lower error rates and is considered more robust and smarter for work tasks.
Their Claude 4 Opus Extended Thinking brings deeper, step-based reasoning, though like all reasoning models, it is slower.
Anthropic was also a pioneer with their open standard, launching the now–widely used Model Context Protocol (MCP), which provides a means for AI systems to share resources, and it’s been taken on by other providers like OpenAI and Google DeepMind.
In short, Claude is great at coding and writing, and good for privacy by default.
Gemini 2.5 Pro Impresses in Reviews
For raw power and capacity, there’s little beating Google’s current top plateau offerings. In fact, Gemini 2.5 Pro dominates the LMArena measures at the time of this writing, basically across the board.
DeepMind’s models also dominate for context length across their top models, with each over one million tokens at the time of this writing (even the lighter-weight Flash and Flash-Lite).
Note that if you’re interested in comparing context windows, you can view these across models on many comparison sites, or sort by context on llm-stats for example, which also lets you easily sort models across their selected benchmarks and includes release dates and more.
And of course, Google models integrate naturally with Google’s entire Workplace ecosystem, which can be a big plus depending on your organization.
Google’s Veo 3 is the latest and greatest AI video generator, if you’re looking for multi-media output, and includes watermarking to fight deepfakes, integrating their SynthID system to identify AI-generated content.
(The number of videos you can create and at what tier has been shifting, but this should be available now to some capacity in the lightest paid option.)
Their selector comes set to “Fast all-around help” by default, which echoes OpenAI GPT-4o, in that this model isn’t their best. But still, it is fast and highly capable and serves for exploratory chats.
For work and harder problems, you can toggle to the “Experimental” 2.5 Pro, which they recommend for math, reasoning, and code.
As with all these offerings, it’s not always readily apparent when a newer model will make the jump between paid plans and show up on the menu, so even if you’re comfortable with the default, it benefits you to explore on a fairly regular basis.
Additional AI Models to Consider
The big three providers outlined above generally mirror each other in value and capacity, though there are idiosyncrasies and strengths and weaknesses among them, and they roll out new models at different times.
But below this tier there are still a number of good options and leading that pack now by capacity is arguably xAI’s Grok.
Grok 4 was recently released with a lot of fanfare and has done very well on many benchmarks, including the very tough Humanity’s Last Exam (where it leads at 44+), though some critics assert xAI has aggressively targeted these benchmarks, and that overall performance does not necessarily match.
Grok 4 integrates well with X and has the most up-to-date training data, making it an effective option for social media related asks.
By design, Grok is also meant to be “straight talking” and cut fluff, though it was in the news last week for generating offensive outputs and needing modification, meaning it may be a model to avoid for client-facing or corporate-geared content generation.
Among open-source models, Meta’s massive new Llama Behemoth was delayed but may arrive any time, and their 3.1 model, like DeepSeek’s R1 and V3 models, has a respectable 128k ballpark for context tokens, and overall are comparable with OpenAI’s GPT-4 level models (and the next tier across the board, Claude 3.7, etc.).
French company Mistral has its own niche, including the Small 3.1 which is among the best in the lightweight class, capable of running on a single GPU.
For companies needing to fully control their own data, fine-tune, and manage costs at the same time, an open-source solution may be essential.
But at this time, these options aren’t among the best-in-class for coding, multi-modal support, or agency/tool use.
Using Deep Research
One of the most useful new features to arrive as of late is Deep Research (aka Research in Claude). Among all three providers (Anthropic, Google, OpenAI) outlined above, this tool is available and is selected below the chatbar.
Note that it runs independently of the chosen model on the selector, which can be confusing.
Deep Research is not the same as asking questions of a given model, as it is geared to send off the AI to gather information (it will run on its own for several minutes).
This leads to a search from a variety of sources, which are then analyzed and compiled in a nice-looking final report.
Note that it may also ask you clarifying questions before going off to do its work, and that use can be limited based on your plan (but at the $20 tier it should be available with several uses per month).
One workflow that’s becoming increasingly popular is to run a Deep Research report for a deeper dive into a central topic or concern, and then feed this back in as a source for a general AI chatbot interface using your preferred model.
Deep Research can do an effective job of comparisons and summaries, applying its own chain of reasoning and giving you something that can be exported into a nice-looking PDF. Note that internet use is required to get the most of it, and Google has additional, multimodal output options, such as generating podcasts or quizzes.
Andrej Karpathy noted on X that he uses Deep Research for about 10% of his chatbot use, and Ethan Mollick has called it a “key AI feature for most people, even if they don’t know it yet.”
In our own experience, Deep Research modes provide a much more effective starting place when focusing on a single topic but are far from error free. We’ve had reports that fail to output to PDF, for example, and include hallucinations of the same kind you find with normal use, though these modes are more thorough and therefore expected to be more reliable.
They also provide sources without being explicitly asked, which makes following up on their data far easier.
PTP and AI Use Cases for Business
At PTP, we work extensively with AI and find it a critical ally across the business.
As this article is focused on the various chat-based offerings of the plateau-leaders, we recommend overall:
- Trying all the major ecosystems, ideally at the $20 tier for comparisons of what they have to offer
- Toggling the different models for each for different tasks and comparing the results
- Utilizing Deep Research for exploring deeper dives into topics, summaries, and analysis
- Comparing the quality of the outputs to open-source offerings, especially if the goal is for on-prem or fine-tuned needs
- Staying agnostic where possible, enabling best-of-breed sampling as the release schedules are staggered (for example we expect to see GPT-5 next as a new plateau)
- Changing your mindset with AI chatbots from querying for data or expertise, to being a two-way conversation with flawed but highly capable partners
- Using these tools to challenge ideas, apply alternate approaches, grab a large pool of options, expand on concepts, and find flaws
- And when in doubt, never ask for one answer when you can get 10, and alter your asks to get all new approaches
And of course, when you’re in need of a partner, consider us.
We love helping companies get up to speed with AI, whether it’s with consulting around getting started, implementing agentic AI testing solutions, or providing the very best AI/ML talent, onsite or off.
Conclusion
If you’ve not already done so, put some regular time aside and just dive in.
At the $20 level for one month, you can’t go wrong with the top three providers outlined here (Google, OpenAI, Anthropic).
As Ethan Mollick recommends, test now “on real work: First, switch to the powerful model and give it a complex challenge from your actual job with full context and have an interactive back and forth discussion.”
Keep asking for changes and compare the results that you get and try Deep Research and multimodal output generation.
While the systems outlined here may soon be out of date, the longer you wait to try them all, the further behind you get.
References
ChatGPT’s GPT-5-reasoning-alpha model spotted ahead of launch and Claude 4 benchmarks show improvements, but context is still 200K, Bleeping Computer
OpenAI’s new reasoning AI models hallucinate more and Elon Musk’s xAI launches Grok 4 alongside a $300 monthly subscription, Tech Crunch
Using AI Right Now: A Quick Guide, One Useful Thing
Which AI Is The Best In July 2025, Fello AI
LLM Leaderboard, llm-stats
Google’s Veo 3 AI video generator is now available to everyone – here’s how to try it, ZDNet
FAQs
How do I decide which ecosystem should be my default/paid option?
Among the choices of OpenAI, Google, and Anthropic, you likely can’t go wrong, depending on your needs. But the best choice is to utilize each as your needs dictate where possible. In short, we could recommend:
- Gemini for Google Workspace, video, and context window
- GPT and o3+ for well-balanced coverage among tasks
- Claude for writing and coding
When is it worth paying for an AI tier vs free offerings?
Where possible, of course, it’s always best to try what you can for free. And tools like Perplexity for search and light research can provide real value without paying. But work-level access to tools from these providers like the highly useful Deep Research, an entry-level buy-in is advisable. This also gives more models to choose from and fewer limits on volume of use.
What advantage does a large context window actually provide?
Context engineering is an emerging specialty in this arena because it can matter a great deal in terms of the quality and type of response.
The context window refers to how much an AI model can ingest, for example, in a given request. A larger window means it can handle more in a single go, such as more lines of code or a larger document.


