


The term “AI-washing” isn’t new. It may have been coined by the AI Now Institute at NYU back in 2019. As far back as 2020, Gartner reported 35% of survey respondents already admitting they were exaggerating their use of AI in marketing materials.
AI capabilities have exploded, as we’ve covered steadily in our AI roundups (our last edition noted frontier models have already hit the median task horizon predicted by superforecasters for the end of the year), and yet still AI exaggeration—by optimists, doomers, and marketers alike—has easily kept pace.
Yet today there’s another AI capability divide that’s just as pronounced. Less cynical and more pragmatic, it’s the gap between productive and ineffective AI implementations.
Voice AI business automation can collapse workflows, complete common customer requests effectively in most cases, personalize messaging and content, and effectively extend reach for both outbound and inbound communications without sacrificing service quality.
It can even reduce errors in the process. This is backed by data (like 70%+ AI first contact resolution rates, 44% first-run engagement rates, 30%+ inbound deflection), and yet it still reads like hype to many.
Why? Because numerous companies are having more fitful results; struggling with edge cases, measurement, and compliance.
Today we look at the human side of AI implementation and its critical role in failures and successes alike.
What’s Going Wrong with Enterprise Voice Automation?
There have been numerous studies showing the scale and potential causes of AI business implementation struggles over the past several years.
Our infographic below pulls stats from McKinsey and BCG, but there are also many from academia, like the source of our banner above (MIT NANDA).
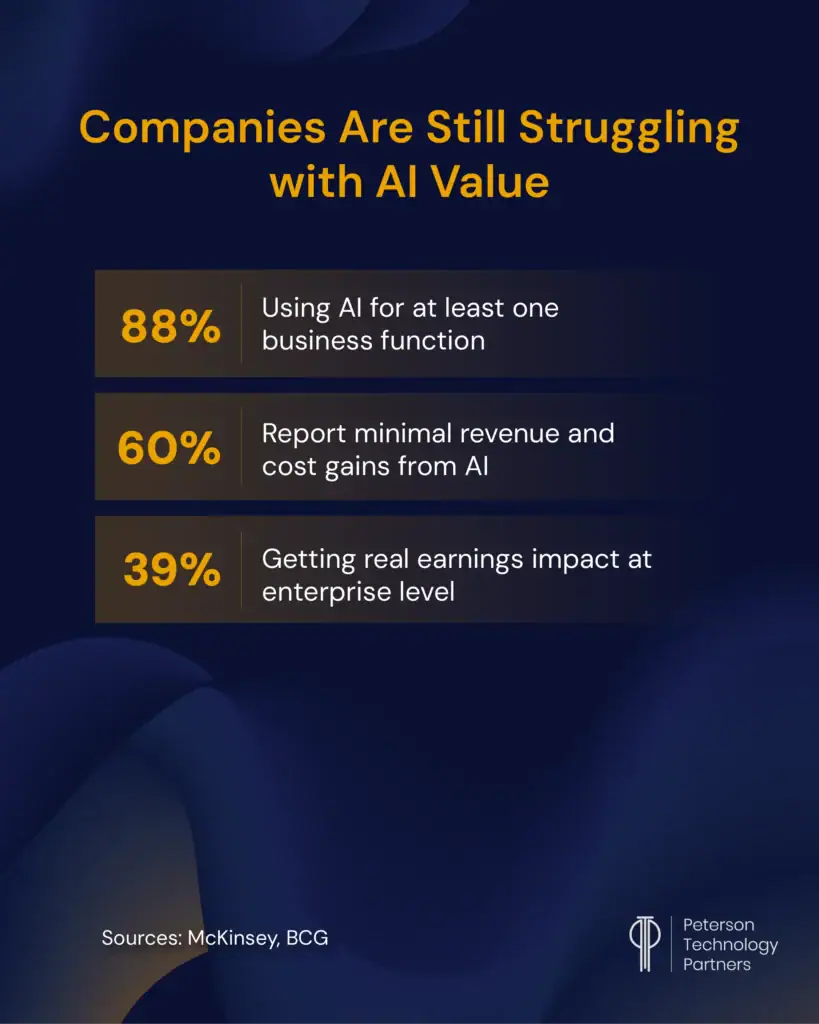
Aside from marketing, most are not focusing on success stories. Maybe Tolstoy’s quote from Anna Karenina applies here, too: “All happy [AI implementations] are alike; each unhappy [AI implementation] is unhappy in its own way.”
The Stanford Digital Economy Lab released a study recently that looks across 50+ happy AI implementations for patterns.
In their section on crossing “the valley of death” to ROI, they report several commonalities:
- Being intentional doesn’t necessarily mean taking a long time. They found the organizational context is critical and reported radically different timelines between companies even using the same use cases and same AI models.
- The learning curve was the leading source of delays (25%), with data quality and prep, regulatory and compliance, and process documentation gaps all tied (at 21%).
- Every single successful implementation (100%) used an iterative approach with the same pattern: start small, learn, and expand.
Overall, their study reported that 77% of the hardest challenges for even successful implementers were non-technological in nature, including change management, data, and process redesign.
Ultimately, they noted that “AI amplifies whatever process it is applied to.”
Things that are broken can get worse in a hurry.
The Rubber Stamp Problem with Human-in-the-Loop AI Oversight
High among common process and compliance problems is human-in-the-loop (HITL). And despite being frequently referenced as a necessity, many remain confused on what it looks like in reality.
Yes, GenAI is fallible. Yes, it can be applied incorrectly to problems, without the right training and yes, it needs guardrails. Yes, it can drift and be easily manipulated. Most everyone agrees humans must be “in the loop” on AI outcomes to ensure accuracy.
The brute force solution is human sign-off or having an AI generating content that’s then given to a human to verify. (HBR described the surge in “workslop” late last year for the surge in content that looks great, needs verification, and provides limited real value.)
Without clear accountability (is the company to blame, the team, the model or software-layer maker?) assigning a human the job of AI review ensures the buck stops somewhere.
But this simple approach, frequently called the “rubber stamp problem,” fails to provide any real oversight for numerous reasons.
AI is far faster than us and can work 24/7 and across multiple channels at once (all reasons it’s beneficial). If a human being is expected to really review all that work, it means only one of two possible outcomes:
- The reviewer skims, failing to provide meaningful review.
- Review becomes the new bottleneck.
But in addition to volume, GenAI’s tendency to create work that looks correct every time makes reviews even harder on a case-by-case basis than checking human work.
Add to this the problem is documented by the International AI Safety Report for 2026 as “automation bias.”
Across randomized experiments, humans have been found less likely to correct erroneous suggestions coming from AI if they are optimistic about AI (or if it requires extra work).
AI Voice Agents Bring Their Own Added Complexities
For voice systems, in addition to oversight, there are also serious considerations needed around compliance and consent. Do-not-call (DNC) lists must be accommodated, opt-outs honored, and AI callers must identify themselves in many regions.
And ultimately even the most effective voice AI systems depend on the data they are given, the rules they follow, the channels in which they work, and the training, readiness, and availability of the humans meant to take handoffs or oversee the systems in the first place.
The stakes for customer trust also can be higher, as they directly engage with the AI.
For compliance, voice systems require staying on top of call recording, summaries, and transcripts for audit purposes as well as keeping control on the handling and storage of caller data.
The high stakes and unique rules surrounding voice AI led PTP to adopt our own five non-negotiables (in-house and in work with customers):
- AI must be disclosed at the start of every call.
- All opt-outs get stored permanently in the CRM.
- DNC lists must get synced before every campaign run.
- All call recordings, transcripts, and AI summaries must be effectively organized and readily accessible for audit.
- Human escalation must occur within 60 seconds on request or at detected distress.
But these only represent the bare minimum.
Getting More Effective Human-AI Collaboration
The internal human-AI interaction is ultimately critical to the success or failure of voice AI initiatives. As discussed above, oversight can’t take away what an AI agent is providing, nor provide a person with an impossible review ask.
The goal, as detailed in research by CSIRO Research Director and UNSW professor Liming Zhu and team, is to move away from a “rubber stamp” system and instead to a system of layered agency. This means AI agents should maintain their operative capabilities to do repeatable work while also facilitating human agency for review and steering. They should provide the right materials to enable a decision free of deeper system concerns.
Their research also provides end-to-end oversight patterns built around common methods, like review (materials checked against subjective criteria) and conformance (checked to objective requirements), aggregating, and prioritizing.
But to do so requires structures and measurement methods are in place and highly functional before launch.
For voice AI, this can mean empowering the agent to identify intent, answer questions and confirm routine details, log across enterprise systems (for example CRM and calendar updates), send reminders, route effectively, and summarize conversations.
HITL here means human team members receive exceptions, ambiguities, cases of elevated emotion or risk, or where relationships or unique accountability are required.
The AI observability role in partnership with legal and other relevant teams ensures compliance before going-live, and also via ongoing review that includes escalation paths, flagged and a standing baseline for routinely sampled call reviews.
Escalation vs Approval in AI Voice Agent Implementation
McKinsey’s research has demonstrated that 65% of companies currently succeeding with AI have well-defined HITL processes that specify when and how outputs need human validation (vs just 23% of other companies).
The Stanford study we led with also considers the optimal level of human oversight.
Their research notes that escalation-based approaches—where the AI autonomously handles 80% of the work with the humans fielding exceptions—were the highest performers, with a median 71% productivity gain.
Approval methods, by contrast, showed just 30% gains.
But they also note that choosing between approaches must be an aspect of strategic design based on error tolerance and task complexity for the use case.
Here again, the gains that a company can potentially reap are extremely dependent on the amount of work an AI system can be allowed to do on its own, leaving human team members to shift their focus to more varied and complex work.
Success or failure often depends on the use case that’s been chosen and how the workflows around it are structured.
Getting Effective Human Oversight for Conversational AI
AI voice automation risks and controls must be established from the ground-up. While this means selecting the right use case, it also means designing conversations that:
- Identify always as AI
- Are fast and transactional
- Offer human transfer within the first 30 seconds
- Include consideration of objection routes
- Leave voicemail that can enable callback to the same agent
- Don’t enable the completion of any transaction that requires human consent
The most productive starting use cases are outbound, proactive, and informational, with no transaction risks at all.
But once a use case has evolved and been tuned and proven by metrics and oversight to be safe and effective, companies can increase their ambitions and handle more complex inbound use cases.
What Real AI Oversight Looks Like
Ineffective Oversight | Actionable Oversight |
“Rubber stamp” problem:
| Layered agency: Includes AI task agency and human to verify, steer, and substitute |
| Automation bias: Humans trust AI results more because of polish/style | Evidence-based review: Recordings, transcripts, and AI summaries with >5% of all calls given weekly review |
| Unclear ownership: User, vendor, team, IT, legal, compliance, or leadership? | AI observability owner: Handles review, tuning, reporting; measurement owners, training owners, |
| Ineffective escalation: Routing for edge cases is too slow or falls in gaps | Clearly defined escalation paths: Escalation triggers are clearly defined with routing method to named queue/role |
| Measurement gaps: Can miss drift, quality, escalation accuracy, downstream costs | KPI scorecards: Clearly defined quality, business, risk metrics with methods, owners, timelines |
| AI lockdown: Agent capabilities are excessively limited to avoid risk | Performance-driven evolution: Use cases, scaling, and AI autonomy driven by results and continued oversight |
Voice AI calls should reach human teams in a variety of ways, including warm transfers (agent introduces the human, and shares full details with recommended next steps), round robin queues (cascading transfers which can include coms-channel notification ala Slack or Teams), scheduled callbacks (with calendar slot booked and confirmation sent via SMS), and reverse transfers (allowing humans to go back to AI for simple follow-up tasks).
Working with an AI Oversight Framework
There are a number of proven frameworks that can help companies stay on top of challenges like these as they work to implement voice solutions.
We’ve written previously on frameworks for GRC (AI and cybersecurity), including our profile of NIST’s CSF 2.0 and AI Risk Management Framework. These help ensure ownership gets defined, risks get mapped, ongoing management detailed, and measurements defined and put in practice.
PTP has shared our own framework specifically for voice AI. Called the VOICE Framework™, it is built around five core pillars that help companies ensure they’re using the right use cases, integrating with the right systems, measuring the right things at effective intervals, and building effective governance and human AI collaboration into the system from the foundations up.
By establishing a highly productive escalation model with clear handoff paths to humans, ongoing oversight, and effective system measurement and improvement, the system helps companies deploy highly productive voice AI systems that are agentic, safe, and compliant.
Ultimately, the goal of the roadmap is to prevent unexpected failures, damages to trust, and compliance or security breakdowns that are currently derailing so many AI pilot programs across industries.
Conclusion: Pairing AI Trust and Automation
Companies are embracing AI but often in ways that are fitful, frenetic, and unreliable. Our widely quoted Stanford study sees AI agents, for example, being highly productive (also 71% median productivity gains vs 40% from high automation) but also lagging in adoption (used in just 20% of cases).
Their research shows that agentic AI succeeds when it is used as “a redefinition of the role of humans and machines in the workflow.”
Voice AI is technologically ready to increase bandwidth and reduce costs. It can enable companies to effectively contact customers they’re neglecting now, improve routine functions like scheduling, and provide much greater self-service capacity at all hours.
The trick is almost entirely in how it’s done.
If your company is in the market for voice AI that is safe, effective, and highly productive from the start, check out our VOICE Framework™ and the full AI voice agent implementation guide.
References
What is AI washing?, Quantum Zeitgeist
AI-Generated “Workslop” Is Destroying Productivity, Harvard Business Review
Designing meaningful human oversight in AI, Zhu, L., Lu, Q., Ding, M. et al.
International AI Safety Report 2026, arXiv:2602.21012 [cs. CY]
The GenAI Divide: State of AI in Business 2025, MIT NANDA
The Enterprise AI Playbook: Lessons from 51 Successful Deployments, Stanford Digital Economy Lab
FAQs
What is human-in-the-loop AI, and why is it important for enterprise voice agents?
Human-in-the-loop (HITL) means humans are involved somehow in work that an AI system does, or in “in the loop” of its workflow. This can mean operation, decision-making, inputs, outputs, safety, and more, often with the goal of ensuring correctness and incorporating human feedback. For voice agents, it is particularly important to get right, as many regions allow for opting-out of AI contact and for cases of complex, emotional, or highly regulated conversations.
How should companies decide what AI voice agents can automate?
The best place to start is with high-volume, repeatable calls with measurable outcomes. They should also have clear boundaries and low risk, and PTP recommends beginning with outbound use cases where possible. Examples include appointment scheduling and reminders, order status updates, backorder notifications, lapsed customer outreach, and after-hours calls.
How does PTP’s VOICE Framework™ support voice AI compliance and oversight?
PTP’s VOICE Framework™ is built around five core pillars (validating use cases, orchestrating workflows, integrating human judgment, controlling risk and protecting trust, and evolving through measurement). It is designed to help companies move effectively along a three-phase journey from use case selection to ongoing monitoring and improvement in ways that ensure both ROI and safety.
Drawn from the company’s experience with both internal and customer AI implementations, it exists to help span the implementation gaps, maintain compliance, and ensure business outcomes before scaling.

